
5090架构详细分析
快速总结
摩尔定律已经失效,老黄这次没活了.
炼丹用
和上一代4090的Ada Lovelace架构所带来的性能提升相比,这次5090的Blackwell(GB202)架构带来的性能提升,更多的是通过优化芯片设计而带来的。 虽说在Die外通过更换内存,提升L3总线宽度和加大内存所带来了一些L3的带宽提升,不过真的会有人用5090跑训练吗?至于TensorCore的FP4? 还是要看工业界用的如何。
游戏用
往好处想想,这一次5090虽然炼丹性能没有特别大的提升,可是游戏性能提升了很多!(特指DLSS4), 再加上内存和位宽都提升了很多,只能说老黄的刀法还是精湛!
渲染用
至于对于渲染用来说,新增加的 Mega Geometry 和 AMP 技术, 以及新一代的RT Core/NVENC/NVDEC 大大加强了渲染性能。
架构与制程:通过设计来增加SM数量
-
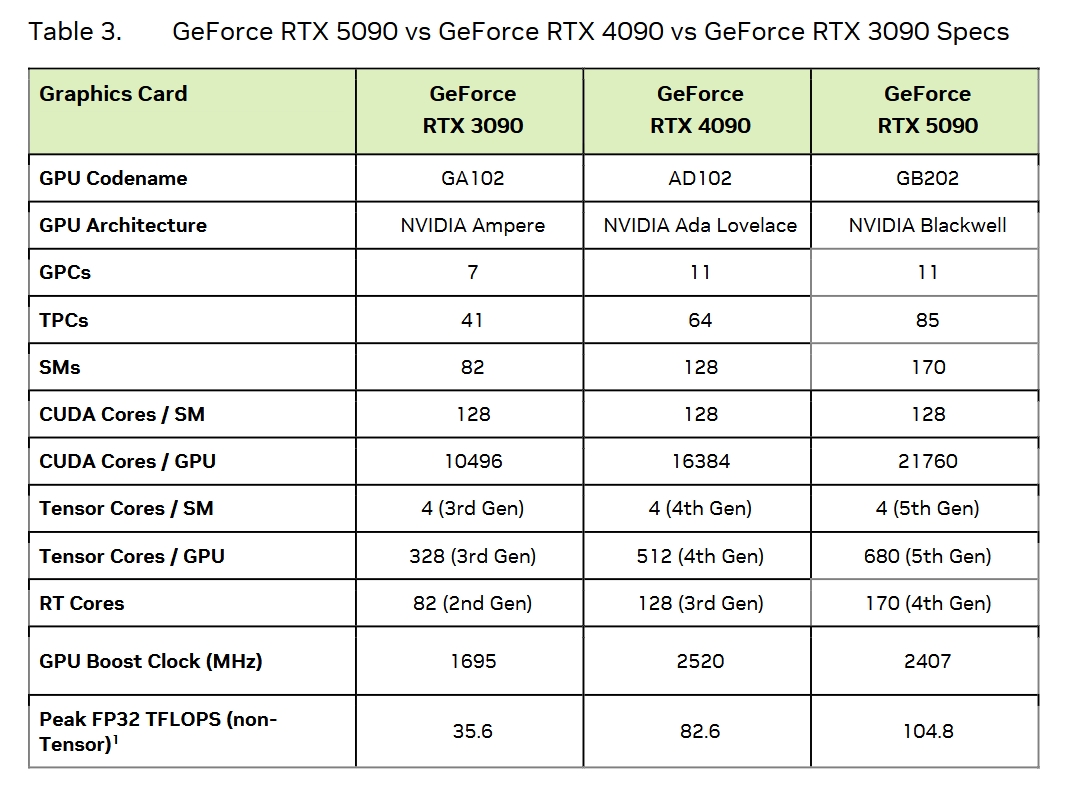
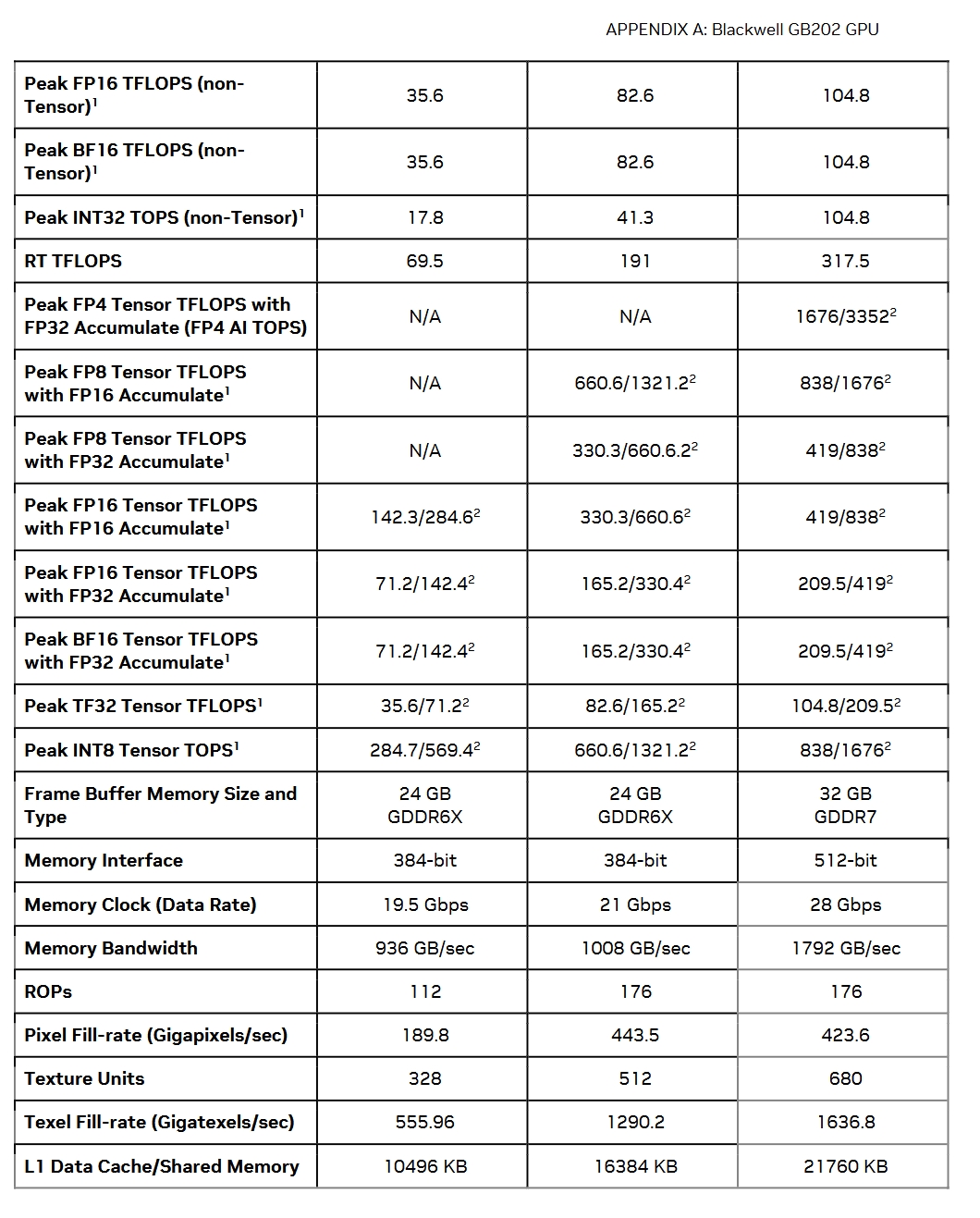
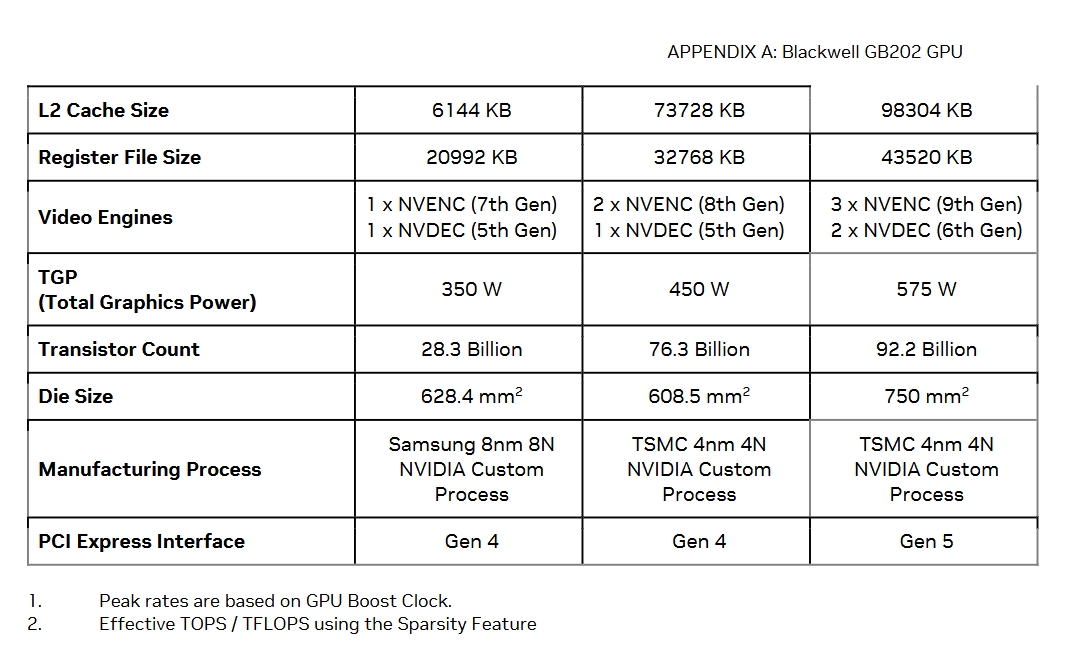
架构升级:从Ada Lovelace到Blackwell,SM(treaming Multiprocessors )数量从128个提升至170个,晶体管数量达922亿(RTX 4090为763亿),为复杂计算任务提供更强动力。
-
延续TSMC 4nm 4N定制工艺,通过优化设计实现更高能效比,在相同功耗下性能显著提升。
总结: BlackWell 没有任何制程上的改变,依旧使用和上一代一样的制程。通过改变设计来增加SM数量提升性能
计算核心: 新增加的Tensor Core FP4/FP6支持
-
CUDA Core:虽然GPC的数量不变,依旧是8个,但是通过在每个GPC中增加了2个TPC,现在CUDA Core总共达到21760(RTX4090为16384),提升了33%。不过看满血的GB202为12 * 8 * 2 * 128=24576 个CUDA Core,看起来依旧是为了良品率,reserve了总计11个TPC。
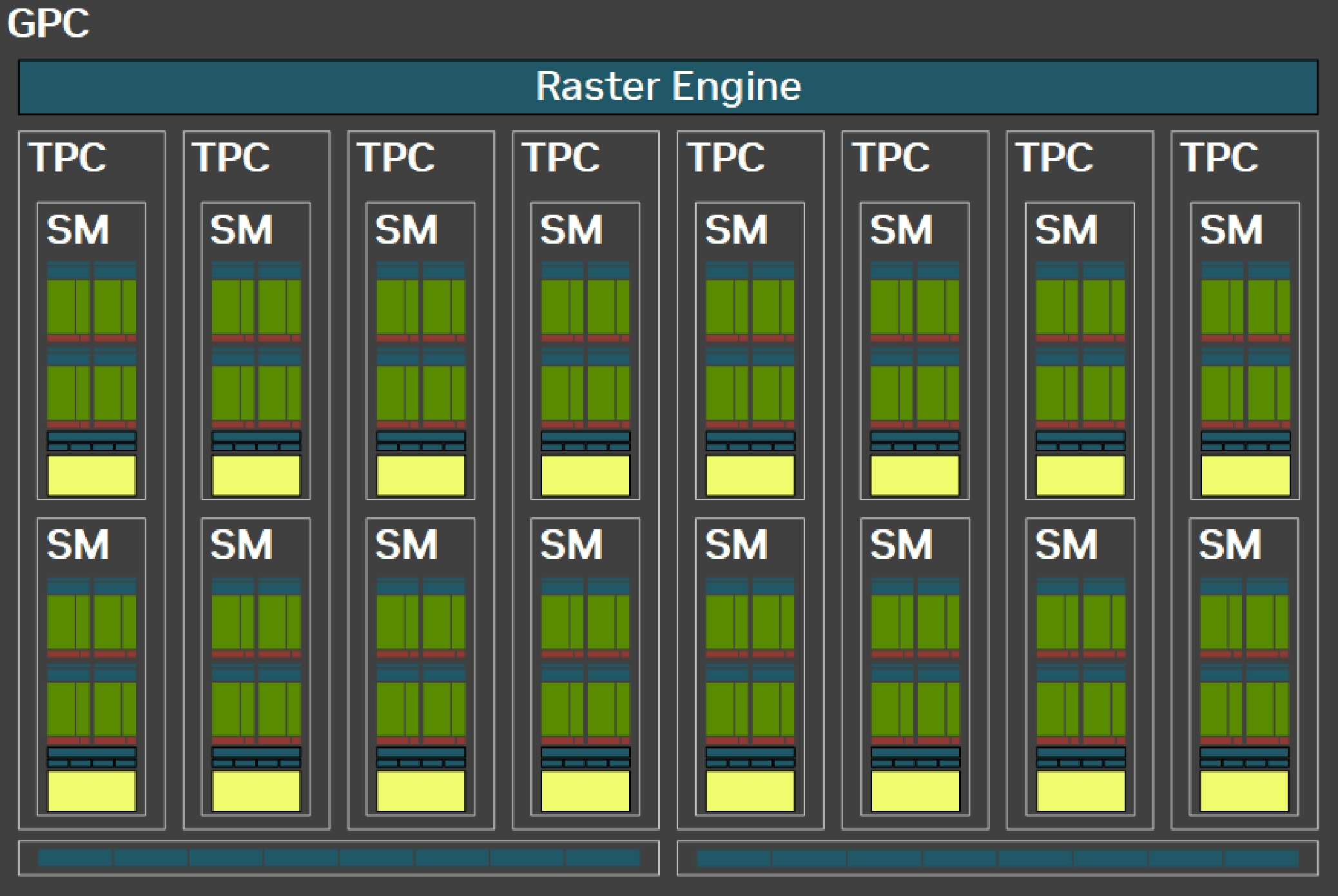
-
SM架构优化: 和上一代fp32 cores和int32 cores 分开不同,这一代把fp32 cores和int32 cores统一了,这其实是满常见的业界做法,可以统一fp32/int32的性能,小幅提升die size的利用率,毕竟同一个cycle内要同时算fp32和int32的场景真的不太多。
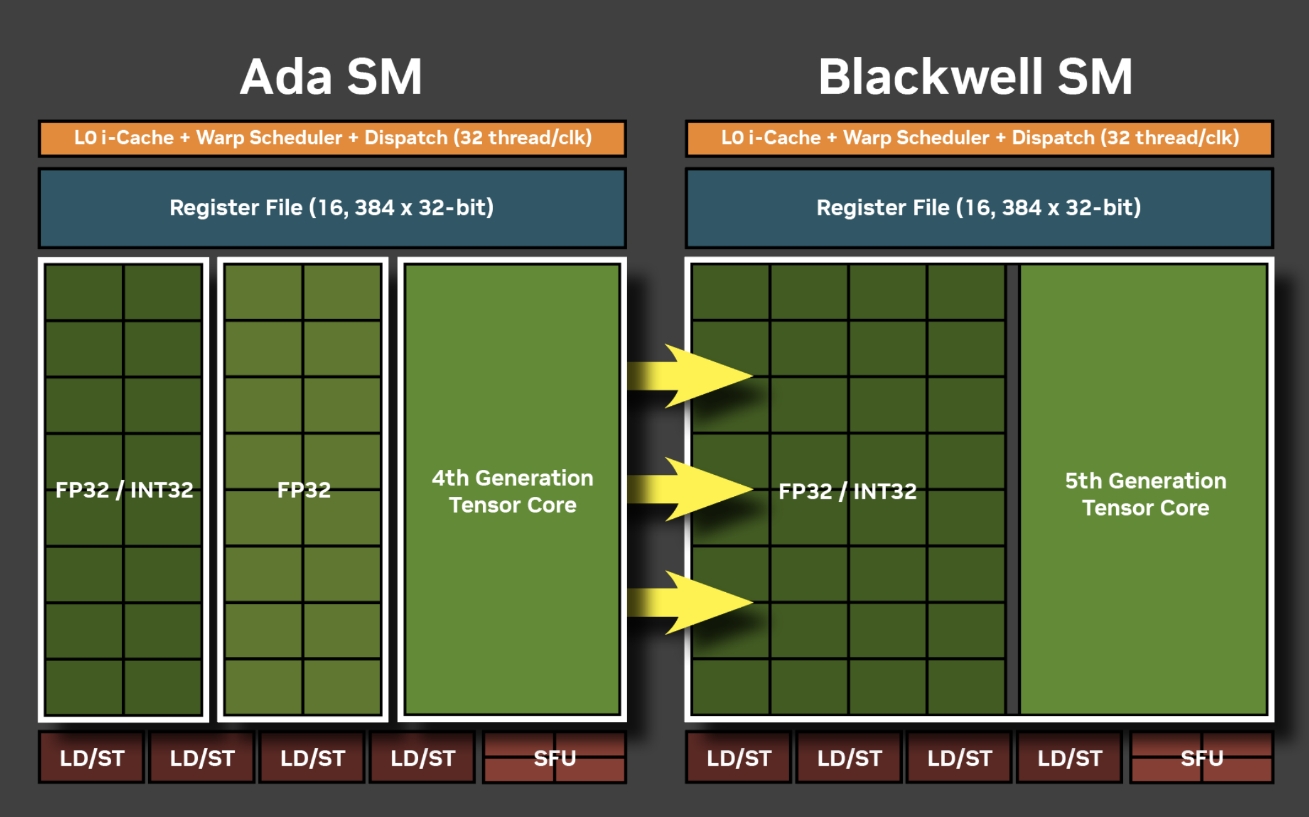
-
Tensor Core:第五代Tensor Core数量增加到680个(RTX 4090为512个),并且 新增支持FP4/FP6精度,AI推理速度提升2倍以上。例如,FP4量化下,Stable Diffusion等大模型推理速度从15秒缩短至5秒, 但是具体效用如何,还需要看工业界如何使用。
-
RT Core:第四代光追核心数量增至170个(RTX 4090为128个),光线追踪性能达317.5 RT TFLOPS(提升66%),支持Mega Geometry技术,可实时渲染数十亿三角形场景。
总结: 只有FP4/FP6的支持是亮点。
内存与带宽: GDDR7上线!
-
显存容量:32GB GDDR7(RTX 4090为24GB GDDR6X),满足8K纹理、AI大模型训练等高负载需求。
-
显存带宽:通过新的技术,把内存带宽从22.4Gbps提升到了28Gbps, 现在5090的L3带宽是1,792 GB/s(提升78%),搭配512-bit超宽接口,彻底释放GPU性能。
-
缓存优化:L2缓存扩容至96MB(RTX 4090为72MB),减少数据延迟,提升光线追踪与AI计算效率。
总结: 1.7TB/S 快媲美前几代HBM的带宽了。
核心技术:重新定义图形与AI的边界
-
AI Management Processor (AMP): 新增加了一个RISC-V的计算核心,用于GPU上下文的调度,减少调度的最小粒度,并且可以进一步摆脱对于CPU的依赖,并且在同时进行打游戏和渲染这种多任务的场景时,提升显卡整体的利用率。
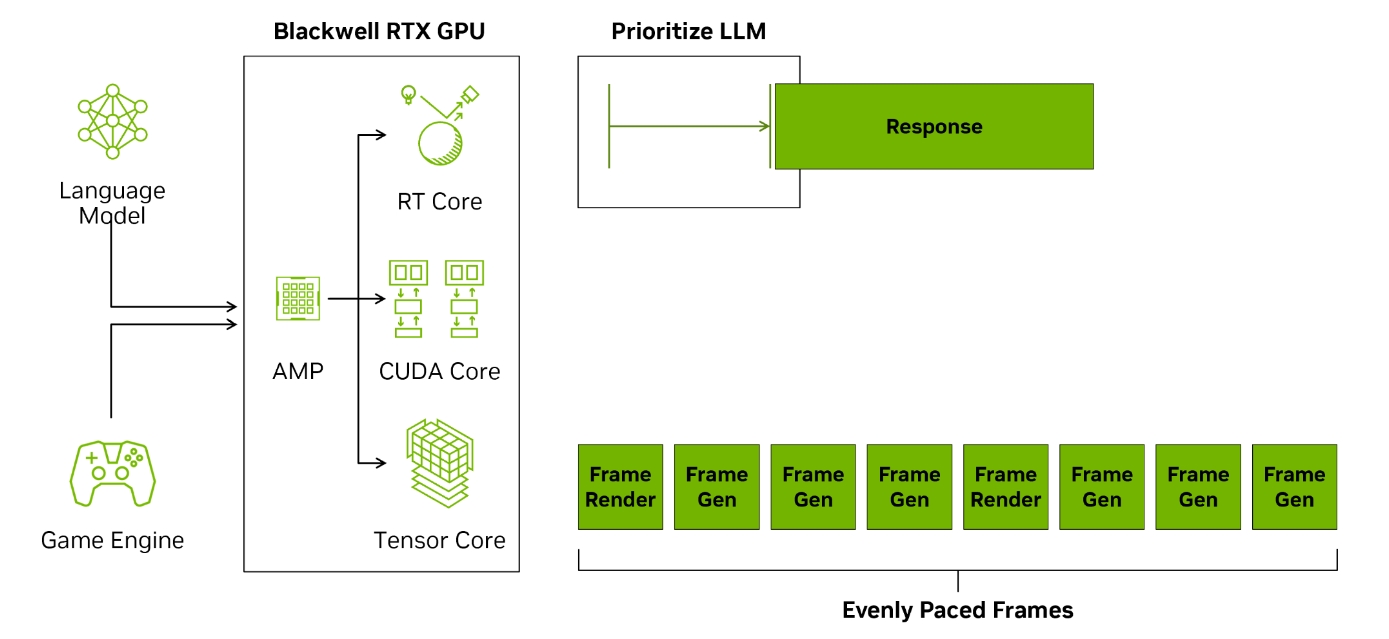
- DLSS 4:多帧生成与Transformer模型
- 多帧生成(MFG):单次渲染生成最多3帧,帧率提升2倍,配合Flip Metering技术优化显示时序,消除画面卡顿。
- Transformer架构:取代传统CNN模型,超分辨率(SR)与光线重建(RR)质量显著提升,动态场景细节更稳定,光线噪点减少50%以上。
- Mega Geometry:复杂场景的终极解决方案
- 通过Cluster BLAS加速结构,将三角形集群作为光线追踪基本单元,减少BVH构建开销,支持Unreal Engine 5 Nanite技术实现全细节光追。
- 第四代RT Core:光线追踪的质变
- 新增 线性扫掠球体(LSS)硬件加速,优化毛发、粒子等精细几何渲染,性能比传统三角形网格(DOTS)提升2倍,显存占用降低5倍。
总结: 硬件没活了,只能从软件想办法提升利用率了。
能效优化:性能与功耗的平衡
- Max-Q技术:
-
动态电源门控:按需关闭闲置模块,功耗降低20%。
-
加速频率切换:响应速度比前代快1000倍,瞬时提升频率应对突发负载。
-
低延迟睡眠:深度睡眠状态进入时间缩短10倍,待机功耗降低50%。
-
- 独立电源轨设计:GPU核心与显存供电分离,优化电压控制,能效比提升15%。
总结: 如果你的代码没有碰到功耗墙,那么只有IDC需要关心这个。
视频与显示:专业级创作与沉浸体验
-
编码性能:第九代NVENC支持4:2:2 H.264/HEVC编码,AV1超高质量模式画质提升15%,导出速度比RTX 4090快50%。
-
解码能力:第六代NVDEC支持4:2:2格式,H.264解码速度翻倍,助力8K视频实时剪辑。
-
显示输出:DP 2.1b UHBR20接口支持8K@165Hz(需DSC压缩)与4K@480Hz,为未来高刷显示器铺路。
总结: 拿来打游戏和渲染的人可能会比较高兴。
总结
RTX5090目前来看,在硬件上已经没办法拿到制程收益的情况下,老黄从软件想办法的提升整卡的利用率,但是对于炼丹来说,看起来还是没有太大的吸引力。不过对于游戏佬和渲染来说,它是AI与图形融合的里程碑,凭借Blackwell架构的暴力硬件、GDDR7的带宽革命,以及DLSS 4、Mega Geometry等黑科技,这张卡真的是强而有力口牙!
详细参数
参考:
- “nvidia-rtx-blackwell-gpu-architecture” nvidia, https://images.nvidia.com/aem-dam/Solutions/geforce/blackwell/nvidia-rtx-blackwell-gpu-architecture.pdf
留下评论